Jamie's personal blog
My name is Jamie Davidson, and I'm a software engineer from Cambridge, England. This website was created in effort to do more technical writing, and encourage me to talk about my side projects.
Project maintained by jamiedavidson Hosted on GitHub Pages — Theme by mattgraham
Identifying black market accounts in League of Legends
This is a writeup of the development process of an automated search and tag system for black market League of Legends accounts. Before we begin… This blog post was made for educational purposes. Automating in game actions is against the League of Legends terms of service and I do not in any way endorse violation of Riot Games’ intellectual property or EULA
If you’re simply interesting in reading the source code for this project, here you go.
So what’s the problem?
If you log in to League of Legends and enter a game playing against AI, you’re highly likely to find a bot or 2 (up to the maximum of 4) on your team. These are accounts which play solely against AI with the end goal of getting to the current level soft cap of level 30, so that they can be sold to players that are looking to skip the grind and get straight in to ranked games.
Some of these accounts are very cheap. A quick Google search reveals offerings anywhere between $15 for a single account, to $1 for 5 or more. I have never tried to buy one, so can’t comment on whether sellers are trustworthy, but can only recommend that you don’t buy them for the following reasons.
These accounts encourage smurfing, which is considered by many to be detrimental to the overall health of a game. If you’re not familiar with the concept, this PCGamer article does a good job at explaining why people do it, why its believed to be a negative issue, and different ways that game developers attempt to combat it.
These accounts are not limited to a specific rank. In fact while watching a couple of youtube videos by SoloRenektonOnly, I spotted some suspicious accounts in his NA Platinum 1 games, which are still active and playing in diamond ELO. Even watching some League of Legends highlights on YouTube, Twitch streamer KarasMai (over 200,000 followers at time of writing) is playing on a suspicious account. It appears to be an account which automatically played Twisted Treeline (3v3) games to get to level 30.
Playing against AI is meant to introduce new players to the game, and new players were (I’m unsure if they still are) required to play some games against AI to get a feel for the game before playing against other players. The rate at which these automated accounts appear in these games mean that new players are almost guaranteed to find one or more, and if they realise what’s happening it can give a negative impression of the game and discourage people from continuing to play.
When speaking to a small number of people who have purchased accounts, I was told that the services that were advertised were for “hand levelled” accounts, meaning a real person has played on them manually from level 1-30. When inspecting the accounts that they’d bought (often in bulk and quite cheaply) the accounts all fit the profile of an automated account. It’s very common for this sort of false advertising to exist in black markets for online games, so it’s not surprising to see it here.
Since writing this software, I have reached out to 100 people who have bought accounts that have been tagged by it. I asked them where they bought the account from and why, and asked if they’d be willing to disclose how much they paid for it. I received a variety of responses and some were open to talking about it. The reasons for purchasing varied from wanting a smurf to replacing a permanently banned account, and one player proudly stated they wanted an account to intentionally feed and flame on when they were in a bad mood to avoid needing to reform their behaviour.
Others were less keen on conversation, telling me to go fuck myself and die. Fair enough.
Recognising patterns in automated accounts
When attempting to identify automated accounts, there are several things that make them stand out from regular players. Their behaviour over the years has changed, so I’ll try to be explicit with old vs current behaviour.
- They’ll typically use the default summoner spells ghost and heal in slots 1 and 2 respectively. This is in spite of quickly being a high enough level to use other summoner spells, and the client highlighting this and recommending trying out other spells. It’s unlikely that a new human player will actively avoid using summoner spells which are objectively better than ghost and heal.
- They typically play against “Intro” (the lowest difficulty) AI. This is because the game almost guarantees a win due to the difficulty of the AI. Even having no human players in the game in theory enables a win.
- When these automated accounts first appeared in League of Legends, they would play continuously, all day, every day. When ban waves started happening for them, they cut back the amount of games they play a day. Nowadays I’ve observed two sets of behaviour for these accounts.
- The first set play between 1 and 10 games per day. It’s uncommon for them to take a break for a day or more.
- Others play 10-20 games in a single long burst, disappear for a few days, and then repeat the process.
- They used to commonly play the same champion every game. They now appear to rotate between champions in the free play pool.
- They used to have very simple behaviour. They would run down a lane, die, repeat a couple of times and then run around or idle in base. This was too obvious behaviour, and they are now far more complex. They now attack and last hit minions and even champions. They no longer receive 0 kills per game, and their K/D/A ratio is a lot more varied from game to game.
- They consistently follow a handful of naming conventions, possibly suggesting that the majority of bots are run by a small handful of different organisations. Either names will be made entirely of random letters OR contain a randomly picked person’s name, with 2-6 letters randomly generated before or afterward.
- They’ll often start off with the Press The Attack/Sorcery rune page, and then pick a random premade rune page and use that forever.
- While many of the accounts I’ve seen stop at level 30, there are some which go on to continue the grind. This is likely because some people look to buy accounts with a large amount of blue essence to unlock more champions for ranked play. These accounts typically sell for slightly more money, because more time has been put in to them.
Because of these patterns, it’s easy to identify many bots by playing a game containing a single bot. There are so many of them, that visiting the 2 profiles I’ve included above reveal a myriad of other bots by looking at their match histories. Manually, it is very easy to get lost in the train of bots. With the help of some software, however, we can leverage automation to make our lives easier. We could crawl https://op.gg to identify, flag and cache names of potential bots starting on a single profile and continue until every trail hits a dead end. I’m suspicious that this approach might not have a finish line.
So why aren’t they all banned?
Before being too critical of Riot for not deploying bans more frequently, lets have a think about what goes in to the decision to ban an account permanently.
You have to be absolutely sure that you’re not about to ban a legitimate player. There are players who have never played a game in the MOBA genre before, or are maybe young enough to not have a lot of experience playing games in general and so will take a while to learn to play the game. These players may have similar behaviour to automated accounts. Even if the success to failure ratio is very close to 100% success, you’ve still removed real people from your game, who will share their experience. A single small mistake can go on to have a real impact on your business.
Even worse, there will be someone out there actively looking to imitate a bot to see if they get caught up in an automated or manual ban. This would be a bit of a PR nightmare if this got out, because anti-cheats ought to be rooted in automated decision making to avoid human error. Alternatively, they should be based on community decisions from trustworthy, knowledgeable players (see Counter-Strike: Global Offensive’s Overwatch system). So can you be 100% sure that they’re not just out to mess with you?
Depending on the technology used for automation, Riot Games may not deploy any detection vectors that catch this custom automation software. Here’s an (albeit slightly out of date) article written by Riot about a couple of their approaches to combat cheating.
League of Legends didn’t have an anti-cheat until a few years ago, and even in its current state it’s quite basic. While it may have done a fine job detecting the publicly available AutoHotkey scripts, this custom software is likely in memory, maybe injected from kernel mode, which alone makes detection a lot more complicated. We’ve seen a couple of newbie anti-cheat blunders fairly recently too, like when Riot decided to close the game if any open window title contained the words “Cheat Engine”, which I feel speaks for itself. I looked for the automation software, as I’m interested in reverse engineering it, but for obvious reasons couldn’t get a hold of it or any developers. Without being able to get your hands on a copy of the software, it can be really hard to write detection vectors for it without being too intrusive with your users.
We could also give Riot the benefit of the doubt and assume that they have a policy of identifying cheaters and delaying a ban. This is common practice in anti-cheat development, as instantly denying access to the game or banning an account can give a cheat developer an indication that they’ve bypassed at least some of your detection vectors. In other words, if you can run a detected cheat and get past the point of being removed from the game, you’ve made progress in bypassing an anti-cheat.
Utilizing the Riot Games API to (attempt to) identify a bot
One of my core values is to avoid criticising without contribution. If I’m going to complain about something, I should do what I can to move conversation in the right direction, ask the right questions, or develop something in an attempt to leave things better than I found them. In software development this is known as the boy scout rule.
The Boy Scout Rule can be summarized as:
Leave your code better than you found it.
Lets start by breaking down our problem of “how can I identify a bot with relatively high confidence?” in to sub-tasks.
- See if I can find the list of names used by the bots, or one that’s close and that I can have confidence in.
- Explore Riot’s APIs to make a plan of action and decide what queries we need to make.
- Load static data to be used by the bot.
- Gather data from Riot’s API and develop the application.
- There are 2 C# libraries available publicly, RiotSharp, and Camille.
- While RiotSharp appears to have been around longer, after a brief dive in to code, Camille has better code quality and is easier to read and understand. One quick thing that I’ve noticed is that at the time of writing neither of them mention anything about implementing pagination handling in their README files, which I may need in the future.
- Data analysis and report generation.
4 sub-tasks to tackle, which can be broken down further if needed. Here are my chosen tools for this problem.
- Postman, to gain some confidence with the Riot API and figure out implementation details. My main questions are as follows
- What’s the rate limiting going to be like? Will I need to implement back-off, or am I unlikely to hit the limit provided I’m looking at one user at a time? Will the response telling me that I’ve hit the limit tell me how long I must wait before I can continue? Not all APIs do this well.
- Will I need to implement pagination? Do I really want/need everything, or will one page of data be enough to give me confidence in my findings?
- What are the filtering and search mechanisms going to be like? Am I going to find a single POST endpoint with a payload for querying data, or is the API going to be a bit more sensibly laid out?
- Am I allowed multiple API keys? If I am, it may make sense to implement a master slave pattern to speed up the automation of looking up data, using as many slaves as I’m allowed API keys. I don’t wish to break the rules, so if the Terms of Service say no then I won’t.
- Visual Studio 2019, because I haven’t spent a lot of time with VSCode yet and new things are scary. Don’t judge me.
- Newtonsoft.Json, which will allow me to easily map responses coming back from the Riot API to instances of objects in C#, and filter out any properties coming back that we don’t want. I haven’t made use of the shiny new
System.Text.Jsonnamespace yet, and would rather not get side-tracked by learning new things. - A small logging library that I wrote called SimpleLog, which allows for formatted logging for C# command line applications. It’s lightweight and easy to use. You’ll see it show up in this project often.
See if I can find the list of names (or one that’s close) used by the bots
Before trying to find the list online, I put together a short list of names which I’ve found by manually searching through https://euw.op.gg. Thankfully, it includes some interesting (see: uncommon) names among the bots, meaning that in theory it will be easier to find a list.
I’ve chosen these names because I believe this will help me narrow down the websites and name lists that they could be from. They originate from different countries, and have different commonly used time periods. Heather is still a common(ish) name to give a child today, but I have yet to meet anyone named Orville in my generation.
After some short investigation, I believe that there are 2 name lists. The first is the name list used in a programming problem presented by Project Euler, called Names Scores. All of the above listed names are present in the list, which contains a total of 5,163 records. The second, a list of “35000+” baby names from the website Amy and Rose.
In order to increase my confidence, I found some more names that weren’t part of my starting list, to see if they were present. Marshall, Hayden and Harriet were present on both lists. Of course I can’t be 100% certain that this is what they’re using, but they’re the most likely candidates I could find online. I’ll be monitoring reports generated by the bot to see if any names aren’t included in either list.
I’m naming this application Casshan, after the Japanese show Casshan: Robot Hunter. Casshan will be written in C# as it’s the language I have the most experience with.
Explore Riot’s APIs to make a plan of action and discover what queries we need to make
Before I can begin writing a library for my queries, I need to know what features I need. The purpose of the publicly available libraries is to give developers full leverage of the API. I’m confident that I don’t need the full feature set, but I also don’t know what I need just yet. So some investigation is needed to clear out the unknown unknowns.
The Riot Games API splits data by geographical region. I play primarily on the EU West server, so the data that I’ll be retrieving will come from euw1.api.riotgames.com. This server is located in Dublin, Ireland and is hosted on Amazon AWS, so my query times from the UK will be minimal. Depending on the success of this project, I may seek out volunteers from other regions to run Casshan.
Riot Games provide some data for constants, such as queue IDs and game types. Looking down the list of queue IDs, I found the ones that I’m primarily interested in:
{
"queueId": 800,
"map": "Twisted Treeline",
"description": "Co-op vs. AI Intermediate Bot games",
"notes": null
},
{
"queueId": 810,
"map": "Twisted Treeline",
"description": "Co-op vs. AI Intro Bot games",
"notes": null
},
{
"queueId": 820,
"map": "Twisted Treeline",
"description": "Co-op vs. AI Beginner Bot games",
"notes": null
},
{
"queueId": 830,
"map": "Summoner's Rift",
"description": "Co-op vs. AI Intro Bot games",
"notes": null
},
{
"queueId": 840,
"map": "Summoner's Rift",
"description": "Co-op vs. AI Beginner Bot games",
"notes": null
},
{
"queueId": 850,
"map": "Summoner's Rift",
"description": "Co-op vs. AI Intermediate Bot games",
"notes": null
},
There are also some deprecated queue IDs, which we’ll include in the queries for good measure:
{
"queueId": 31,
"map": "Summoner's Rift",
"description": "Co-op vs AI Intro Bot games",
"notes": "Deprecated in patch 7.19 in favor of queueId 830"
},
{
"queueId": 32,
"map": "Summoner's Rift",
"description": "Co-op vs AI Beginner Bot games",
"notes": "Deprecated in patch 7.19 in favor of queueId 840"
},
{
"queueId": 33,
"map": "Summoner's Rift",
"description": "Co-op vs AI Intermediate Bot games",
"notes": "Deprecated in patch 7.19 in favor of queueId 850"
},
{
"queueId": 52,
"map": "Twisted Treeline",
"description": "Co-op vs AI games",
"notes": "Deprecated in patch 7.19 in favor of queueId 800"
},
This will make it easy for us to deduce whether an account is likely automated; automated accounts will have a large number of games vs AI, and knowing these queue IDs will make it easy to filter through match histories. Knowing the deprecated queue IDs will likely mean we catch some number of bots which were made and sold some time ago.
The next part of the puzzle is figuring out where we get match histories from. The Match v4 endpoints have a very feature rich searching/filtering mechanism, but they require we know an encrypted account ID, which doesn’t have any real documentation, at least on this page.
There’s also a set of summoner endpoints, which includes an endpoint to retrieve an encrypted summoner/account ID, which is what we need to interact with the match history endpoint.
Querying for the summoner name YvonnevJdNbK, we retrieve the IDs that we need.
{
"profileIconId": 3543,
"name": "YvonnevJdNbK",
"puuid": "lZAH8DRyJxSbP8Z14VTL4-BfwT_zUwj3eEqPm18fMB6Zq1B3sQUI7B8ItODkQkliVaj2NqYSIanOaQ",
"summonerLevel": 30,
"accountId": "36WtxyrYlnTCGC6ey335O2AqLQJmIis_1SwAZ8TpZoBnfYmJWQH97n0w",
"id": "9WpjCGhwuQaPza9xAaIonXSJxp_XPUsT_zVEx1_NAvsI4ct_",
"revisionDate": 1579444557000
}
The get match list endpoint has feature rich filtering, so lets see what we get if we specify no filtering criteria first.
{
"matches": [
{
"lane": "NONE",
"gameId": 4373074413,
"champion": 555,
"platformId": "EUW1",
"timestamp": 1579443163328,
"queue": 830,
"role": "DUO_SUPPORT",
"season": 13
},
{
"lane": "NONE",
"gameId": 4373058458,
"champion": 35,
"platformId": "EUW1",
"timestamp": 1579441565542,
"queue": 830,
"role": "DUO_SUPPORT",
"season": 13
},
... etc
],
"endIndex": 100,
"startIndex": 0,
"totalGames": 191
}
So by default, we get the results back in pages of 100. Seeing the totalGames field answers one of the questions I asked earlier: “will I need to implement pagination?” The answer is probably not, I don’t care about reading all of the data, even this number of matches is excessive.
If we use the queueId parameter for filtering, and use the value 830 that we learned about earlier, here’s what we get back.
{
"matches": [
{
"lane": "NONE",
"gameId": 4373074413,
"champion": 555,
"platformId": "EUW1",
"timestamp": 1579443163328,
"queue": 830,
"role": "DUO_SUPPORT",
"season": 13
},
{
"lane": "NONE",
"gameId": 4373058458,
"champion": 35,
"platformId": "EUW1",
"timestamp": 1579441565542,
"queue": 830,
"role": "DUO_SUPPORT",
"season": 13
},
...etc
],
"endIndex": 100,
"startIndex": 0,
"totalGames": 166
}
So 166 out of 191 total games have been played against intro bots. Repeating the process for 840 reveals 38 games have been played against beginner bots. This account has not played any games against intermediate bots, so using 850 responds 404 as no games match the filter criteria. IMHO this is poor design, an empty collection of matches should be returned instead. Nevertheless, the presence of 404 in this scenario is something I needed to know about for the library.
So for argument’s sake, lets assume that we don’t care about the match data. We can continue to tweak the filter parameters, and the endpoint is happy to accept 0 for both start and end indices, and will tell us the number of games that match the query:
{
"matches": [],
"endIndex": 0,
"startIndex": 0,
"totalGames": 166
}
So with 3 queries, we can take a summoner name and deduce the percentage of games that have been played in the co-op vs AI mode.
Something that we haven’t seen yet is the rune page and summoner spells used by the player in a single match. This information is not returned from the match history endpoint, but is displayed in a league of legends player’s match history screen.

I suspect that the rest of the data can be retrieved by querying the matches/{matchId} endpoint. Taking 4373074413, a gameId present in the response from the match list endpoint we can see a large breakdown of the game.
Using notepad++ and the json viewer plugin, reading through large response payload is more manageable.
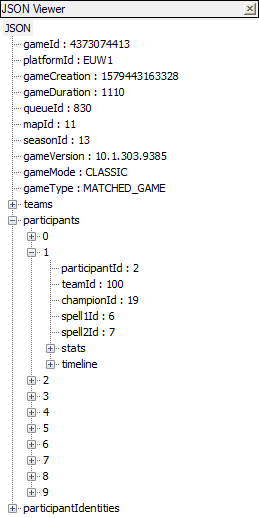
The chunks that I’m interested in are firstly the participantIdentities entry for the player we’re investigating:
{
"player": {
"currentPlatformId": "EUW1",
"summonerName": "YvonnevJdNbK",
"matchHistoryUri": "/v1/stats/player_history/EUW1/2351401518803776",
"platformId": "EUW1",
"currentAccountId": "36WtxyrYlnTCGC6ey335O2AqLQJmIis_1SwAZ8TpZoBnfYmJWQH97n0w",
"profileIcon": 3543,
"summonerId": "9WpjCGhwuQaPza9xAaIonXSJxp_XPUsT_zVEx1_NAvsI4ct_",
"accountId": "36WtxyrYlnTCGC6ey335O2AqLQJmIis_1SwAZ8TpZoBnfYmJWQH97n0w"
},
"participantId": 5
}
Interestingly, the match history uri appears to be an internal use only or deprecated API, as the endpoint appears to exist but my API key does not authorize me to view the data from it.
Using that participantId, we can retrieve the relevant data from the participants array
"participants": [
{
"spell1Id": 6,
"participantId": 5,
"timeline": {
// not interesting for now
},
"spell2Id": 7,
"teamId": 100,
"stats": {
// not interesting for now
},
"championId": 555
}
]
spellId1 and spellId2 look like they could be what we want, and Riot provide data to confirm this, through a public project called Data Dragon. A list of summoner spells should reveal what 6 and 7 mean for summoner spells. (I recommend JSON viewer for Chrome to make the reading experience easier on the eyes and brain).
Unsurprisingly, 6 is SummonerHaste (a lot of league’s original naming is “inspired by” DOTA), and 7 is SummonerHeal.
The timeline returns data as deltas and refers to the differences between the participant and their lane opponent. Given that the game is against AI opponents, this data is unlikely to prove useful. It looks like this:
"timeline": {
"lane": "NONE",
"participantId": 5,
"csDiffPerMinDeltas": {
"0-10": 1.7600000000000002
},
"goldPerMinDeltas": {
"0-10": 244.60000000000002
},
"xpDiffPerMinDeltas": {
"0-10": 127.02000000000002
},
"creepsPerMinDeltas": {
"0-10": 0.6000000000000001
},
"xpPerMinDeltas": {
"0-10": 297.8
},
"role": "DUO_SUPPORT",
"damageTakenDiffPerMinDeltas": {
"0-10": -107.70000000000002
},
"damageTakenPerMinDeltas": {
"0-10": 293.8
}
}
The last thing to do is find the runes used in the game. As mentioned previously, after the first game played the bots tend to randomly pick a rune page and stick with it, making no deviations from the recommended rune pages.
This information lives in the stats object returned in the participant data.
Runes are labelled perk0 to perk6, and are IDs for the runes used during the game. statPerk0 to statPerk2, aren’t documented by Riot, but due to existing game knowledge, I know that these are part of the rune page, giving small bonus stats for the game.
"stats": {
// K/D/A ratio may allow for some pattern recognition
"kills": 2,
"deaths": 2,
"assists": 2,
// Items bought may have patterns
"item0": 3052,
"item1": 3074,
"item2": 0,
"item3": 0,
"item4": 0,
"item5": 0,
"item6": 3340,
// Which rune types were used, this isn't that interesting
"perkPrimaryStyle": 8100,
"perkSubStyle": 8000,
// Runes used
"perk0": 8112,
"perk1": 8139,
"perk2": 8138,
"perk3": 8135,
"perk4": 9111,
"perk5": 8014,
"statPerk0": 5005,
"statPerk1": 5008,
"statPerk2": 5002,
// There may be some threshold in the number of minions killed that we can look for patterns with
"totalMinionsKilled": 26,
// Stats related to wards, I wonder if any of the bots will have placed wards?
"visionWardsBoughtInGame": 0,
"sightWardsBoughtInGame": 0,
"visionScore": 0,
"wardsKilled": 0,
"wardsPlaced": 0
},
It’s back to Data Dragon we go, this time looking at the item list. There doesn’t seem to be a public page to view rune data, so I’ll instead download the entire data library, since I prefer to use a local copy of the data over requesting it from the web on application start.
So that’s all my ducks in a row. In order to see if we’ve found a bot:
- Check the summoner name, and see if it’s made up of random letters and/or numbers, or contains a name in our list.
- Take a summoner name and get the account ID for it.
- Check the number of bot games played. A large amount of bot games played is a flag.
- Gather a list of match IDs from the bot games played.
- Enumerate the games and look for patterns in X matches to increase confidence that we’re looking at a bot account.
- While enumerating the games played, cache all of the participants found to later check, and continue the bot hunt Ad infinitum.
An outlier in any of this criteria should not determine whether we stop an investigation, but rather should individually increase or decrease our confidence that we’ve found a black market account.
Load static data to be used by the bot
I’m choosing to tackle data loading first, purely out of personal preference. I believe that focusing on data first gives you a strong foundation to build your application on, as you have a deeper understanding of the shape of your expected input and output and provides an opportunity to spot problems as early as possible.
So here’s a small JSON utility to help me load the static data from disk
using System.IO;
using Newtonsoft.Json;
namespace Casshan
{
internal static class JsonUtil
{
public static T LoadJsonFromFile<T>(string path) where T : class
{
if (!File.Exists(path))
{
throw new FileNotFoundException($"File at path {path} was not found");
}
var fileText = File.ReadAllText(path);
return JsonConvert.DeserializeObject<T>(fileText);
}
}
}
Next we need something to actually load. This is how the rune data is laid out for us:
- The JSON document starts with a collection of groups.
- Each group has an ID, key, icon, name, and a collection of slots.
- Each slot has a collection of possible runes for that slot
- Each rune has an ID, key, icon, name, and a description
Here’s an example, using the first rune type from the data file:
{
"id": 8100,
"key": "Domination",
"icon": "perk-images/Styles/7200_Domination.png",
"name": "Domination",
"slots": [
{
"runes": [
{
"id": 8112,
"key": "Electrocute",
"icon": "perk-images/Styles/Domination/Electrocute/Electrocute.png",
"name": "Electrocute",
"shortDesc": "<snip>",
"longDesc": "<snip>"
},
...etc
]
},
{
"runes": [
...etc
]
},
{
"runes": [
...etc
]
},
{
"runes": [
...etc
]
}
]
},
This is a lot of data that we don’t actually want, all we really want is a mapping of rune IDs to rune names. We have a couple of options, NewtonsoftJSON allows us to write bindings to navigate the tree and only serialize the parts that we care about. This also allows us to easily load more data should we decide that we want it in the future.
A JSON binding for a single rune looks like this:
using Newtonsoft.Json;
namespace Casshan.Bindings.Static
{
internal sealed class RuneJsonBinding
{
[JsonProperty(Required = Required.Always)]
public int Id { get; set; }
[JsonProperty(Required = Required.Always)]
public string Name { get; set; }
}
}
We don’t have to do anything extra to tell Newtonsoft JSON to ignore the rest of the document, it will automatically filter out anything we haven’t explicitly included.
Required = Required.Always will cause Newtonsoft JSON to throw an exception if a part of the JSON document that we care about is missing. This will ensure that the payload we’re parsing is complete, and help to catch any bugs with data retrieval and manipulation that we haven’t already considered.
Now that we have JSON bindings in place, it’s time to load the data from disk and store it in a data structure. I’ll be using a dictionary which contains the rune ID as a key and the rune name as a value.
using System;
using System.Collections.Generic;
using System.Linq;
using Casshan.Bindings.Static;
namespace Casshan
{
internal class Program
{
private static IReadOnlyDictionary<int, string> m_Runes;
private static void Main(string[] args)
{
m_Runes = new Dictionary<int, string>();
var runeCategories = JsonUtil.LoadJsonFromFile<RuneCategoryJsonBinding[]>
($@"{Environment.CurrentDirectory}\data\runesReforged.json");
// Take all of the runes in all of the slots, and transform them to a dictionary
m_Runes = runeCategories.SelectMany(s => s.Slots)
.SelectMany(s => s.Runes)
.ToDictionary(r => r.Id, r => r.Name);
Console.WriteLine($"Loaded {m_Runes.Count} runes.");
// Output the first rune's ID and name to test that it worked
var firstRune = m_Runes.First();
Console.WriteLine($"{firstRune.Key}, {firstRune.Value}");
}
}
}
Running the program yields the output
Loaded 63 runes.
8112, Electrocute
So we have rune data loaded, and now we can repeat the process for items and summoner spells.
Loaded 63 runes.
8112, Electrocute
Loaded 243 items.
1001, Boots of Speed
Loaded 14 summoner spells.
21, Barrier
This data will be useful for generating a report explaining the decisions taken when flagging an account as suspicious.
Gather data from Riot’s API and develop the application
Now it’s time to start interacting with the API to retrieve the data needed to flag an account. Lets make a simple repository, starting with gathering the encrypted account ID needed to interact with the matches endpoints.
We only need a couple of methods for a summoner repository at the moment, which will retrieve account details by summoner name or account ID. This requires a simple interface
using Casshan.Domain;
namespace Casshan.Repositories
{
internal interface ISummonerRepository
{
Account GetAccountBySummonerName(string summonerName);
Account GetAccountById(string accountId);
}
}
Where Account is a POCO to hold the Summoner Name and Account ID from the response.
Each repository that I make will require some mechanism to communicate with the API. I’m using the HttpClient class from the System.Net.Http namespace. Rather than require each repository instantiate their own instance of HttpClient, I’m going to pass a factory function to each repository via its constructor which will ensure consistency across every repository.
using System;
using System.Net.Http;
using Casshan.Bindings.Dynamic;
using Casshan.Domain;
using Casshan.Exceptions;
using Casshan.Logging;
using Newtonsoft.Json;
namespace Casshan.Repositories
{
internal sealed class SummonerRepository : ISummonerRepository
{
public SummonerRepository(Func<HttpClient> createClient, ILog log)
{
m_CreateClient = createClient
?? throw new ArgumentNullException(nameof(createClient));
m_Log = log ?? throw new ArgumentNullException(nameof(log));
}
public Account GetAccountBySummonerName(string summonerName)
{
using (var client = m_CreateClient())
{
var response = client.GetAsync($"summoner/v4/summoners/by-name/{summonerName}").Result;
var responseContent = response.Content.ReadAsStringAsync().Result;
var accountBinding = JsonConvert.DeserializeObject<AccountJsonBinding>(responseContent);
return new Account(summonerName, accountBinding.AccountId);
}
}
public Account GetAccountById(string accountId)
{
using (var client = m_CreateClient())
{
var response = client.GetAsync($"summoner/v4/summoners/by-account/{accountId}").Result;
var responseContent = response.Content.ReadAsStringAsync().Result;
var accountBinding = JsonConvert.DeserializeObject<AccountJsonBinding>(responseContent);
return new Account(accountBinding.Name, accountBinding.AccountId);
}
}
private readonly Func<HttpClient> m_CreateClient;
private readonly ILog m_Log;
}
}
We’ll ignore the fact that we’re not handling any failure response codes for now, I have a plan of action for this later.
In Program.cs, which contains the entry point for this application we’ll define the factory function and pass it off to all repositories that we use.
private static HttpClient CreateHttpClient()
{
var client = new HttpClient(new ExpectedFailureResponseHandler(new HttpClientHandler(), m_Log))
{
BaseAddress = new Uri("https://euw1.api.riotgames.com/lol/")
};
client.DefaultRequestHeaders.Add("X-Riot-Token", Settings.Default.APIKey);
return client;
}
The Settings class is just a place where Visual Studio allows free form data storage per application per user.
After moving the static data loading out to a private method, it’s time to test out the repository!
private static void Main(string[] args)
{
LoadStaticData();
var summonerRepository = new SummonerRepository(CreateHttpClient);
var account = summonerRepository.GetAccountBySummonerName("YvonnevJdNbK");
Console.WriteLine($"{account.SummonerName}, {account.AccountId}");
}
Success! We received Level 30, zX3Gt11r0C1w54rJGZYNrFylHYhc6_g-FL5v2AZ5c9vAQCAztrzYyqHE
Manually testing this in Postman shows that it’s correct and can now be used in a matches repository:
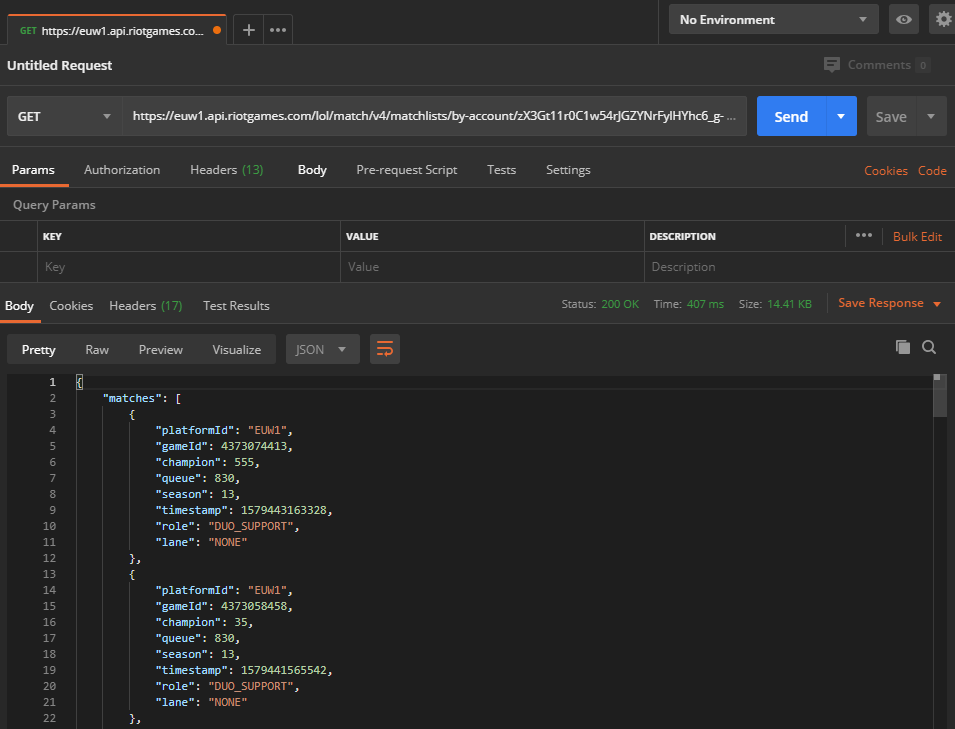
And repeating the same process for a match repository gives us the following surface for the first slice of functionality:
using System.Collections.Generic;
namespace Casshan.Repositories
{
internal interface IMatchRepository
{
int GetGameCount(string accountId);
int GetBotGameCount(string accountId);
}
}
As a proof of concept for the repository, I want to see how many games they’ve played vs how many bot games they’ve played. In doing so, I came across a caching problem that Riot Games have said is “low priority, because the workaround is simple”, where not providing a high-ish start index only returns a small subset of games. We can mitigate this by sending an impossibly high start index, like 123456789
private static void Main(string[] args)
{
LoadStaticData();
var summonerRepository = new SummonerRepository(CreateHttpClient);
var matchRepository = new MatchRepository(CreateHttpClient);
var account = summonerRepository.GetAccountBySummonerName("yvonnevJdNbK");
var allGames = matchRepository.GetGameCount(account.AccountId);
var botGames = matchRepository.GetBotGameCount(account.AccountId);
Console.WriteLine($"{account.SummonerName}, {account.AccountId}");
Console.WriteLine($"Player vs AI games: {botGames}/{allGames}");
}
Unsurprisingly, a large number of this account’s games are bot games. It takes around 191 games to get to level 30, apparently, depending mostly on the length of the game.
Level 30, zX3Gt11r0C1w54rJGZYNrFylHYhc6_g-FL5v2AZ5c9vAQCAztrzYyqHE
Player vs AI games: 262/265
Now it’s time to start pulling information about matches. Simple method, we can strip down the response payloads to contain just the match IDs, since that’s all we’re interested in. To avoid hammering the API too hard while testing, I’m going to restrict the repository to retrieving 10 bot game IDs for now.
public IEnumerable<string> GetMatchIds(string accountId, int begin = 0, int end = 10)
{
using (var client = m_CreateClient())
{
var response = client.GetAsync($"match/v4/matchlists/by-account/{accountId}?queue=830&queue=840&queue=850&endIndex={end}&startIndex={begin}").Result;
var responseContent = response.Content.ReadAsStringAsync().Result;
var binding = JsonConvert.DeserializeObject<MatchesJsonBinding>(responseContent);
return binding.Select(m => m.GameId);
}
}
Testing it out, we now have the 10 most recent IDs for our test account.
Level 30, zX3Gt11r0C1w54rJGZYNrFylHYhc6_g-FL5v2AZ5c9vAQCAztrzYyqHE
Player/AI games: 262/265
4373074413
4373058458
4372993313
4372967764
4372971542
4372817010
4372882185
4372718279
4372755061
4372752856
Before moving on and adding new features, there’s a simple improvement we can make to the repository layer.
There’s a lot of repeated code in our matchRepository now, and all of our public methods will be doing roughly the same thing. * Make request to URL * Deserialize response to JSON binding * Do some sort of data manipulation, mostly unique to each method * Return POCO, or primitive
We can mitigate the duplicated code by creating a generic method for GETting some JSON from a public endpoint.
private T GetJson<T>(string path) where T : class
{
using (var client = m_CreateClient())
{
var response = client.GetAsync(path).Result;
var responseContent = response.Content.ReadAsStringAsync().Result;
return JsonConvert.DeserializeObject<T>(responseContent);
}
}
And now our public methods get a lot simpler, easier to read, and adding new functionality is trivial:
public int GetGameCount(string accountId)
{
var binding = GetJson<GameCountBinding>
($"match/v4/matchlists/by-account/{accountId}/");
return binding.TotalGames;
}
public int GetBotGameCount(string accountId)
{
var binding = GetJson<GameCountBinding>
($"match/v4/matchlists/by-account/{accountId}?queue=830&queue=840&queue=850");
return binding.TotalGames;
}
public IEnumerable<string> GetMatchIds(string accountId, int begin = 0, int end = 10)
{
var binding = GetJson<MatchesJsonBinding>($"match/v4/matchlists/by-account/{accountId}?queue=830&queue=840&queue=850&endIndex={end}&startIndex={begin}");
return binding.Matches.Select(m => m.GameId);
}
This leaves retrieving a match by ID, and then Casshan has the minimum necessary features for interacting with the Riot API.
The match binding is a bit more complicated, as there are many top level objects that we need to filter through to get the data we need. By creating my own POCO rather than returning the binding created from the response, we get a chance to reorganise the data at the repository layer to make further manipulation easier after the repository layer is done with the request.
The JSON bindings for match data is quite large:
using Newtonsoft.Json;
namespace Casshan.Bindings.Dynamic
{
internal sealed class SingleMatchJsonBinding
{
[JsonProperty(Required = Required.Always)]
public ParticipantJsonBinding[] Participants { get; set; }
[JsonProperty(Required = Required.Always)]
public ParticipantIdentityJsonBinding[] ParticipantIdentities { get; set; }
}
internal sealed class ParticipantJsonBinding
{
[JsonProperty(Required = Required.Always)]
public int ParticipantId { get; set; }
[JsonProperty(Required = Required.Always)]
public int Spell1Id { get; set; }
[JsonProperty(Required = Required.Always)]
public int Spell2Id { get; set; }
[JsonProperty(Required = Required.Always)]
public ParticipantsStatsJsonBinding Stats { get; set; }
}
internal class ParticipantsStatsJsonBinding
{
[JsonProperty(Required = Required.Always)]
public int Item0 { get; set; }
...items
[JsonProperty(Required = Required.Always)]
public int Kills { get; set; }
[JsonProperty(Required = Required.Always)]
public int Deaths { get; set; }
[JsonProperty(Required = Required.Always)]
public int Assists { get; set; }
[JsonProperty(Required = Required.Always)]
public int Perk0 { get; set; }
...perks
[JsonProperty(Required = Required.Always)]
public int TotalMinionsKilled { get; set; }
[JsonProperty(Required = Required.Always)]
public int VisionWardsBoughtInGame { get; set; }
...vision stats
}
internal sealed class ParticipantIdentityJsonBinding
{
[JsonProperty(Required = Required.Always)]
public int ParticipantId { get; set; }
[JsonProperty(Required = Required.Always)]
public ParticipantIdentityPlayerJsonBinding Player { get; set; }
}
internal sealed class ParticipantIdentityPlayerJsonBinding
{
[JsonProperty(Required = Required.Always)]
public string AccountId { get; set; }
[JsonProperty(Required = Required.Always)]
public string SummonerName { get; set; }
// SummonerId is absent for AI participants, so Required.Default allows us
// to accept a binding without the field and set SummonerId to null in those cases
[JsonProperty(Required = Required.Default)]
public string SummonerId { get; set; }
}
}
This is not an insignificant amount of data. Making a POCO for this binding will need some data reshuffling. What I want from an object describing a single match is
- The list of players from that game. We already have an account object, so we can reuse that.
- The data for the participants that we’re interested in. In this case, just the one that we’re currently investigating.
- Runes used
- Spells used
- Items bought
- Vision data
- Minions killed
Each of these sets of data should be organised in to their own objects to make analyzing more convenient. A POCO for a single match object ends up looking like this:
using System;
using System.Collections.Generic;
using System.Linq;
namespace Casshan.Domain
{
internal sealed class Match
{
public IReadOnlyCollection<Account> HumanParticipants { get; }
public IReadOnlyCollection<int> RuneIds { get; }
public SummonerSpellPair SpellIds { get; }
public VisionStats TargetVisionStats { get; }
public int MinionsKilled { get; }
public Match(IEnumerable<Account> humanParticipants,
IEnumerable<int> targetRuneIds,
SummonerSpellPair targetSpellIds,
VisionStats visionStats,
int minionsKilled)
{
if (humanParticipants == null)
{
throw new ArgumentNullException(nameof(humanParticipants));
}
RuneIds = targetRuneIds?.ToArray() ?? throw new ArgumentNullException(nameof(targetRuneIds));
SpellIds = targetSpellIds;
var humans = humanParticipants.ToArray();
if (humans.Contains(null))
{
throw new ArgumentException("Must not contain null", nameof(humanParticipants));
}
HumanParticipants = humans;
TargetVisionStats = visionStats;
MinionsKilled = minionsKilled;
}
}
}
Where the RuneIds, SpellIds, Vision stats and MinionsKilled are from the perspective of the player that we’re investigating.
Retry Handling
When using an online service over any period of time, there will be times when the request isn’t fulfilled as expected. Errors may occur during retrieval, the service may be unavailable, or we may hit a request limit. For this reason, it’s important that the application is prepared to handle this so that it can retry or quit depending on the circumstances.
We can write a class which inherits from DelegatingHandler, which can be slotted in to our HttpClient to handle requests and responses. One example status code to check is 429, which represents the TooManyRequests response. In the case that we receive a 429, there should be a header information us of how long to wait. If there’s not, we’ll back off for a minute and try again.
These status codes and headers are defined by spec rfc-2616 from Fielding, et al. These specs are generally agreed upon as “the way things are done”, and aim to provide consistency to minimise the amount of work required for services to communicate. This doesn’t guarantee that all services such as APIs are written this way, as they’re all written by people.
// HttpStatusCode enum doesn't contain a "TooManyRequests", so casting to int is probably fine here.
if ((int)response.StatusCode == 429)
{
if (response.Headers?.RetryAfter?.Delta == null)
{
m_Log.Log("Got rate limit response, but Riot didn't tell us how long to wait.", LogLevel.error);
m_Log.Log("Waiting for 1 minute and trying again...", LogLevel.error);
Thread.Sleep(TimeSpan.FromMinutes(1));
}
else
{
m_Log.Log($"Hit rate limit, backing off for {response.Headers.RetryAfter.Delta.Value}", LogLevel.warning);
Thread.Sleep(response.Headers.RetryAfter.Delta.Value);
}
// Retry the call after waiting
return await base.SendAsync(request, new CancellationToken());
And we can repeat the process for other failure responses, such as 503, service unavailable.
Data analysis and report generation
The final piece of the puzzle is to analyse the data that we’ve retrieved and turn it in to a meaningful report for each account that we analyse. Before tackling analysis, let’s focus on handling our output. We can create a report logging class that we can pass to analysis modules, allowing them to add sections to the report.
using System.Collections.Generic;
using Casshan.Domain;
namespace Casshan
{
internal interface IReportLog
{
void StartReport(Account account);
void AddReportItem(string sectionName, int sectionSuspicion, IEnumerable<string> reportLines);
void FinishReport();
}
}
Writing an interface for this allows us to write multiple implementations and swap them out very easily, as consumers will only be provided with the contract that is the interface. For now, let’s start with implementing a report log system using Files on disk.
using System;
using System.Collections.Generic;
using System.Linq;
using Casshan.Bindings.Report;
using Casshan.Domain;
using Casshan.Logging;
namespace Casshan
{
internal sealed class FileReportLog : IReportLog
{
private readonly ILog m_Log;
private ReportJsonBinding m_CurrentLog;
private string m_SummonerName;
public FileReportLog(ILog log)
{
m_Log = log ?? throw new ArgumentNullException(nameof(log));
}
public void StartReport(Account account)
{
m_CurrentLog = new ReportJsonBinding
{
SummonerName = account.SummonerName,
AccountId = account.AccountId,
ReportItems = new List<ReportItemJsonBinding>()
};
m_SummonerName = account.SummonerName;
m_Log.Log($"Log for {m_SummonerName} started", LogLevel.success);
}
public void AddReportItem(string sectionName, int sectionSuspicion, IEnumerable<string> reportLines)
{
m_CurrentLog.ReportItems.Add(new ReportItemJsonBinding
{
SectionSuspicion = sectionSuspicion,
SectionName = sectionName,
ReportLines = reportLines.ToArray()
});
m_Log.Log($"Added {sectionName} section to report", LogLevel.success);
}
public void FinishReport()
{
m_CurrentLog.SuspicionRating = m_CurrentLog.ReportItems.Sum(i => i.SectionSuspicion);
JsonUtil.SaveJsonToFile($@".\Reports\{m_SummonerName}.json", m_CurrentLog);
m_Log.Log($"Log for {m_SummonerName} finalised", LogLevel.success);
}
}
}
These reports are backed by a JSON binding, which contains a summoner name, account ID and a list of report sections. Each section and overall report is tagged with a suspicion rating, allowing for a grading of 0 to X (where X is the sum of each section’s maximum rating) instead of a black and white “yes or no”. I simply don’t know what this number will be yet, and I imagine it will change as more sections are added.
Analysis will be done by 1 of 2 types of modules. One will look at naming patterns, the other at gameplay patterns. These interfaces end up quite simple.
namespace Casshan.Analyzers
{
internal interface INameAnalyser
{
void AnalyseName(string name);
}
}
using System.Collections.Generic;
using Casshan.Domain;
namespace Casshan.Analysers
{
internal interface IMatchAnalyser
{
void AnalyseMatches(IEnumerable<Match> matches);
}
}
The aim for a match analyser is to take a single slice from each of the matches and compare and draw conclusion from them. By splitting out the logic for each slice of the matches, it becomes much easier to manage and extend in the future.
As an example, here’s the analyser for minions killed in a match. It’s the shortest of them, please refer to the repository if you’re interesting in the rest.
using System.Collections.Generic;
using System.Linq;
using Casshan.Domain;
namespace Casshan.Analyzers
{
internal sealed class MinionsKilledAnalyzer : IMatchAnalyzer
{
private readonly IReportLog m_ReportLog;
public MinionsKilledAnalyzer(IReportLog reportLog)
{
m_ReportLog = reportLog;
}
public void AnalyzeMatches(IEnumerable<Match> matches)
{
var matchesArray = matches.ToArray();
var noKills = matchesArray.Count(m => m.MinionsKilled == 0);
m_ReportLog.AddReportItem("Minion Analysis", 0, new []
{
$"Player killed no minions in: {noKills} games.",
$"Min killed: {matchesArray.Min(s => s.MinionsKilled)}",
$"Max killed: {matchesArray.Max(s => s.MinionsKilled)}",
$"Average killed: {matchesArray.Average(s => s.MinionsKilled)}"
});
}
}
}
I’m unsure of any patterns that may arise here, so for now it’s best to default the sectionSuspicion to 0 for minion analysis. Once some reports have been generated, we can revisit and tweak the suspicion rating for this section depending on what the data looks like.
For name analysis, our rules are laid out as follows
- Does it contain one of the names from our list of suspicious names? If it does, we should strip it from the name and pass the rest on to be analysed by layers further down.
- The rest of our name is expected to contain alternating upper and lower case letters. We can iterate over the rest of the name to see if it alternates casing.
using System;
using System.Collections.Generic;
using System.Linq;
namespace Casshan.Analyzers
{
internal sealed class PredefinedNameStrippingAnalyzer : INameAnalyzer
{
private readonly IReportLog m_ReportLog;
private readonly INameAnalyzer m_UnderlyingAnalyzer;
private readonly string[] m_SuspiciousNames;
public PredefinedNameStrippingAnalyzer(IReportLog reportLog,
IEnumerable<string> suspiciousNames,
INameAnalyzer underlyingAnalyzer)
{
m_ReportLog = reportLog ?? throw new ArgumentNullException(nameof(reportLog));
m_UnderlyingAnalyzer = underlyingAnalyzer
?? throw new ArgumentNullException(nameof(underlyingAnalyzer));
m_SuspiciousNames = suspiciousNames.OrderByDescending(x => x.Length).ToArray();
}
public void AnalyzeName(string name)
{
foreach (var n in m_SuspiciousNames)
{
if (name.StartsWith(n) || name.EndsWith(n))
{
var stripped = name.Replace(n, "");
m_ReportLog.AddReportItem("Suspicious Name Analysis", 1, new []
{
$"Player name {name} contained suspicious name {n}"
});
m_UnderlyingAnalyzer.AnalyzeName(stripped);
return;
}
}
m_ReportLog.AddReportItem("Suspicious Name Analysis", 0, new []
{
$"Player name {name} did not contain a suspicious name."
});
m_UnderlyingAnalyzer.AnalyzeName(name);
}
}
}
Receiving the name YvonnevJdNbK will strip the name Yvonne and pass vJdNbK to the layer below, which can verify whether or not that matches our casing pattern. Instead of iterating the string and checking characters one by one, we can loosely infer whether or not it matches our pattern by checking the number of upper and lower case characters.
using System;
using System.Linq;
namespace Casshan.Analyzers
{
internal sealed class CasingPatternNameAnalyzer : INameAnalyzer
{
private readonly IReportLog m_ReportLog;
public CasingPatternNameAnalyzer(IReportLog reportLog)
{
m_ReportLog = reportLog
?? throw new ArgumentNullException(nameof(reportLog));
}
public void AnalyzeName(string name)
{
var upper = name.Count(char.IsUpper);
var lower = name.Count(char.IsLower);
if (Math.Abs(upper - lower) <= 1)
{
m_ReportLog.AddReportItem("Name Pattern Analayis", 1, new []
{
$"Name {name} matched casing pattern"
});
return;
}
m_ReportLog.AddReportItem("Name Pattern Analayis", 0, new []
{
$"Name {name} did not match casing pattern"
});
}
}
}
While this will also match strings such as aaaAAA and BBaaB, I believe that this is a good thing, in case the naming patterns for these automated accounts change in the future.
Now that we have our analysis code complete, it’s time to tie it together and make use of it in the running program. By utilising the composite pattern, we can layer our analysis in to a single class and reduce the work required by the consumer of the code. The composite pattern can be used regardless of whether ordering is important.
using System.Collections.Generic;
using System.Linq;
using Casshan.Domain;
namespace Casshan.Analyzers
{
internal sealed class CompositeMatchAnalyzer : IMatchAnalyzer
{
private readonly IReadOnlyCollection<IMatchAnalyzer> m_MatchAnalyzers;
public CompositeMatchAnalyzer(IEnumerable<IMatchAnalyzer> matchAnalyzers)
{
m_MatchAnalyzers = matchAnalyzers.ToArray();
}
public void AnalyzeMatches(IEnumerable<Match> matches)
{
var matchesArray = matches.ToArray();
foreach (var analyzer in m_MatchAnalyzers)
{
analyzer.AnalyzeMatches(matchesArray);
}
}
}
}
and by providing “factory” functions, we can create the composite analyzer at runtime.
private static IMatchAnalyzer CreateCompositeAnalyzer()
{
var runes = JsonUtil.LoadJsonFromFile<RuneCategoryJsonBinding[]>
($@"{Environment.CurrentDirectory}\data\runesReforged.json")
.SelectMany(s => s.Slots)
.SelectMany(s => s.Runes)
.ToDictionary(r => r.Id, r => r.Name);
var summonerSpells = JsonUtil.LoadJsonFromFile<SummonersJsonBinding>
($@"{Environment.CurrentDirectory}\data\summoner.json")
.Data.ToDictionary(s => s.Value.Key, s => s.Value.Name);
return new CompositeMatchAnalyzer(new IMatchAnalyzer[]
{
new RunesAnalyzer(m_ReportLog, runes),
new MinionsKilledAnalyzer(m_ReportLog),
new SummonerSpellAnalyzer(m_ReportLog, summonerSpells),
new VisionAnalyzer(m_ReportLog)
});
}
Our program’s flow can be boiled down to:
- Take the first account to analyse, which should be an account which is quite suspicious. You’ll see this referred to as “patient zero”.
- Analyse the account
- Analyse its name first.
- Gather and analyse its matches, and check for previous names on the account while doing so. Analyse that name if one is found.
- Cache all the “Non-AI” participants in the games, and add those to a list to be analysed.
We then enter a loop which will likely continue forever, where we check to see if we’ve already analysed the account the account by looking for an existing report. As time passes, the list of accounts to analyse will grow rapidly, as we’ll be caching up to 200 participants per account we analyse. For this reason, I’ve put a cap on the limit of accounts in the “queue” of 1000 for now. The cap is a soft cap, meaning that it can grow past 1000, but will not be added to while the size of the list is 1000 or more.
It’s time to test out the application, we’ll provide our test subject YvonnevJdNbK as patient zero, and watch it go as it generates a report and moves on to the next.
The generated report can be viewed on disk, and by serializing it to JSON we can use this data later for further analysing, rather than look at them by hand. Lets take a look at the report generated for the account that started off this journey, YvonnevJdNbK
{
"SummonerName": "YvonnevJdNbK",
"AccountId": "zX3Gt11r0C1w54rJGZYNrFylHYhc6_g-FL5v2AZ5c9vAQCAztrzYyqHE",
"SuspicionRating": 15,
"ReportItems": [
{
"SectionName": "Game analysis",
"SectionSuspicion": 2,
"ReportLines": [
"All games played: 265",
"Bot games played: 262"
]
},
{
"SectionName": "Suspicious Name Analysis",
"SectionSuspicion": 1,
"ReportLines": [
"Player name YvonnevJdNbK contained suspicious name Yvonne"
]
},
{
"SectionName": "Name Pattern Analayis",
"SectionSuspicion": 1,
"ReportLines": [
"Name vJdNbK matched casing pattern"
]
},
{
"SectionName": "Rune Analysis",
"SectionSuspicion": 6,
"ReportLines": [
"Used Electrocute 50 times.",
"Used Taste of Blood 50 times.",
"Used Eyeball Collection 50 times.",
"Used Ravenous Hunter 50 times.",
"Used Triumph 50 times.",
"Used Coup de Grace 50 times."
]
},
{
"SectionName": "Minion Analysis",
"SectionSuspicion": 0,
"ReportLines": [
"Player killed no minions in: 0 games.",
"Min killed: 4",
"Max killed: 76",
"Average killed: 22.92"
]
},
{
"SectionName": "Summoner Analysis",
"SectionSuspicion": 3,
"ReportLines": [
"Player used 1 pairs of summoner spells over 50 games",
"Used Ghost and Heal 50 times."
]
},
{
"SectionName": "Vision Analysis",
"SectionSuspicion": 2,
"ReportLines": [
"Player placed 17 wards over 50 games",
"Player placed an average of 0.34 wards per game",
"Player had 12 vision score across 50 games",
"Player had an average vision score of 0.24 per game"
]
}
]
}
Wrapping up
I left Casshan running for several days, over which it accumulated over 3,538 reports. This is a good start, as Riot’s rate limit only allows for the investigation of 2 accounts per minute on average with a single API key. There were some hiccups and crashes to account for that I haven’t talked about.
As it turns out, the data that it gathered is still a tad unreliable. It turns out that I neglected to strip single character names from the list of suspicious names, and so almost every name was treated as suspicious and increased the suspicion rating by 1.
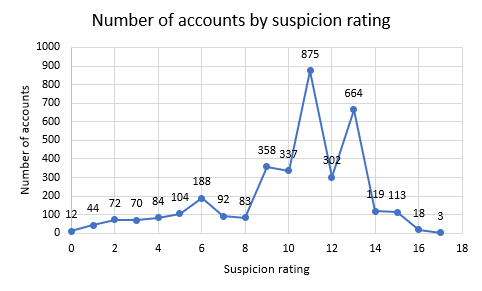
Of the 3,538 accounts observed, 531 accounts have been observed to have changed name, indicating that they have been purchased by a player. There are likely some that were purchased and have not had a name change, but I have yet to investigate the data further.
Future work
While developing Casshan, I was made aware that I was missing out on accounts which automatically played both ARAM games and Twisted Treeline games. Rather than start investigating accounts from these game modes, I’d prefer to complete my investigation of accounts that play against AI. I’d be interested in doing a blind run through some accounts from other game modes and see how well my findings stack up against ARAM and Twisted Treeline accounts. This will be a good indication of how their behaviour has changed over the years.
I’m aware that I haven’t included any analysis of items purchased. In the end, it appeared that the items bought and their buy order were randomised within a set list of items, and varied per champion. Rather than spend a lot of effort on pinning down these patterns I thought it best to push on with the easier portions of analysis, and I believe that I’ve nailed down a solid formula. I’d like to revisit this in the future to see if I can spot some patterns.
I’d like to query the rank of each account, to get an idea of how many of these purchased accounts have gone on to play ranked games and see what the average rank, kill/death/assist ratio is for accounts that have been purchased. The list goes on, and that’s for another time.
If you’re still reading, thank you!
Some special mentions from analysing the output data from Casshan
- 7 summoner names containing “Corona”, “COVID-19” or “bat soup”
- 13 summoner names containing a racial slur, unsurprisingly
- 1 summoner name containing a “your mother” joke